As discussed in the Cluebase introduction, the original Cluebase data was gathered from a one-time process run on my local machine. At the time, I just wanted to get decent data quickly, so I could focus on developing the API, so there was little consideration for data quality. Additionally, putting effort into the reusability and stability of this one-time process would have been a waste.
In other words, there's a lot of work to do in the scraping process. Not much of the existing scraper is usable, so it seems best to just start fresh with a new focus on doing it the right way.
Scraping Goals
1. Data Freshness
Probably the biggest oversight in the original process was that it was meant to be run only once. After running the scraping process a single time, there was no easy way to run it again to update the data. In order to include newly aired clues, I would need to redownload all html files temporarily, parse the clues from each, load them into the database skipping any duplicates, and then generate a new data dump to use within the database container.
The new web scraping process should be able to grab the latest data incrementally, which means it needs to track what has been downloaded already, and notice any possible updates.
Additionally, the process should be able to run in an automated setting to keep the database up to date without my manual intervention--no more image builds just to insert into the database.
2. Coupled Scrape/Load process
Previously, the scraping process included parsing the clues from the HTML and loading them into the db. This meant that in order to change any parsing/loading/formatting logic I would need to redownload every html page, which would take hours using a respectful rate limit for the fragile J! Archive servers.
Scraping links and downloading the HTML should be separate from parsing and loading the clues. By keeping a data lake of raw HTML, I can iterate on the parse/load process as many times as necessary, while only having to download each HTML page once, saving hours of waiting on rate limited requests. Doing so will also greatly aid in solving the challenges in the actual load process.
Implementation
So, we want to crawl the webpages of J! Archive, downloading new game/clue files as we move along. Thankfully, web crawlers are about as old as the web itself.
Generally, a web crawler loads an HTML page, parses the HTML to grab all link tags, and queue them each to visit next. An extra-intelligent crawler would maybe use a smart queue that prioritizes highly ranked pages (by traditional PageRank, visits, traffic, update frequency, or other factors), but we should be able to leverage our pre existing knowledge of the archive site to make things simpler for ourselves.
J! Archive
Let's take a look at J! Archive and see that. Looking at the website calls to mind a more classic era of the internet, and its simplicity makes it relatively easy to see how we can crawl through its games in a simple way.
/listseasons.php
/showseason.php?season=<id>
/showgame.php?game_id=<id>
The listseasons page holds a table of all seasons, with each season having a reference to its
showseason page. There's also some potentially useful info of how many games each season has.
Here's what it looks like to a human user:
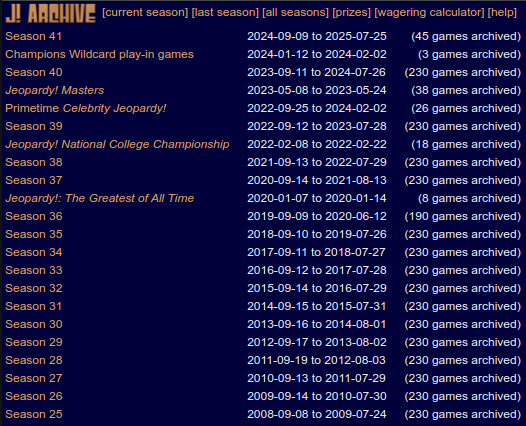
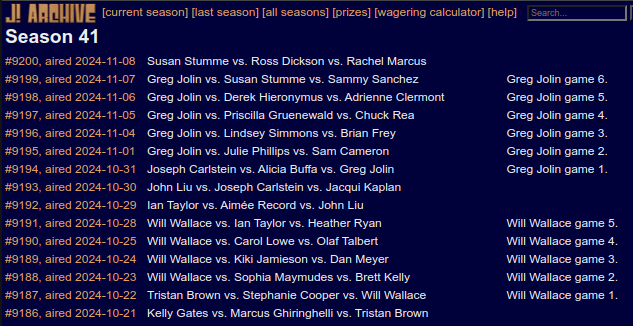
Drilling down one layer of links into the showseason pages, we can see a similar structure. The
page holds a table of all games in the season, with each game having a
reference to its showgame page.
And just one layer down, once we're at the showgame level, the clue texts and solutions are
present directly in the
HTML. We can stop here! Downloading this HTML will give the next parse/load process all the info it needs.

With ~40 seasons of a few hundred games each, we get a total of ~10,000 game files. This is a manageable enough number that I think the simplest approach is to go down the site map layer-by-layer, downloading the list of seasons, then each of the seasons, and then each of the games for each season.
Dev progress:
Currently: Focus on keeping good raw HTML data.
- Downloading season list HTML
- Scraping season list HTML for season links, then downloading those HTML files
- Scraping season links for game links, then downloading those HTML files
Current problems I'm running into are related to the process being long and flaky. While the current flakiness comes from me starting and stopping the process frequently due to active development, network and file actions are inherently flaky, so a long running process dependent on the stability of these is asking for problems.
The constant start and stop of the process raises the following concerns:
- Data integrity: How do we know a file was fully written, or properly written. How do we know a request completed successfully, and returned the full HTML we want.
- Processing status: How do we know when we've already processed an HTML link. Can we skip files we already have to try to just pick back where we left off? If we do, how do we know when a file is out of date, and actually needs to be updated?
TODO: add some validation checks on html files. Most of the
Only intelligence is that it will not overwrite a html file that already exists
- is this how it should work? what if a page exists but is only partially complete (this happens every night!)
- maybe won't matter if there's a scheduled "refresh" that ignores overwrite protection